Chapter2 索引优化
2.1 背景知识
2.1.1 性能下降原因
- 查询语言不合理
- 索引失效
- 关联表过多
- 服务器调优及各个参数设置
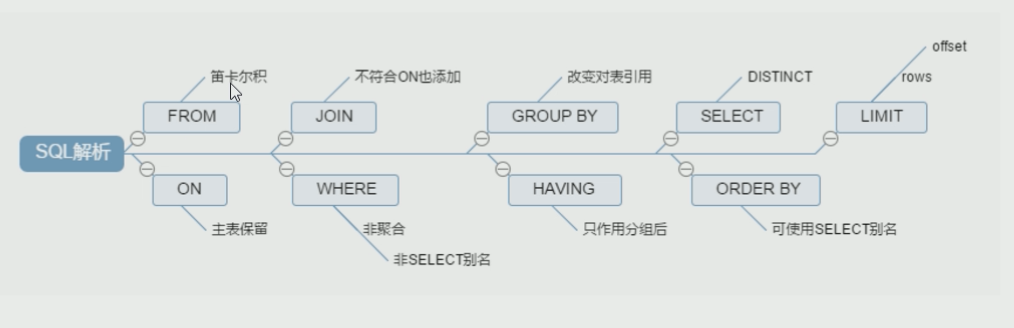
2.1.2 SQL 执行顺序
手写
select -> from -> on -> where -> group by -> having -> order by机读
2.1.3 七种 Join
INNER JOIN
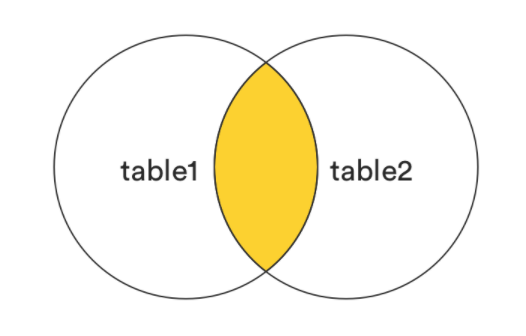
SELECT * FROM table1 INNER JOIN table2 ON table1.key = table2.key;FULL [OUTER] JOIN
![FULL [OUTER] JOIN](https://raw.githubusercontent.com/JabinHao/mihs/master/blog/MySQL/2-1-2_2.png)
SELECT * FROM table1 FULL JOIN table2 ON table1.key = table2.key;FULL [OUTER] JOIN without the intersection
![FULL [OUTER] JOIN without the intersection](https://raw.githubusercontent.com/JabinHao/mihs/master/blog/MySQL/2-1-2_3.png)
SELECT * FROM table1 FULL JOIN table2 ON table1.key = table2.key WHERE table1.key IS NULL OR table2.key IS NULL;LEFT [OUTER] JOIN
![LEFT [OUTER] JOIN](https://raw.githubusercontent.com/JabinHao/mihs/master/blog/MySQL/2-1-2_4.png)
SELECT * FROM table1 LEFT JOIN table2 ON table1.key = table2.keyLEFT [OUTER] JOIN without the intersection
![LEFT [OUTER] JOIN without the intersection](https://raw.githubusercontent.com/JabinHao/mihs/master/blog/MySQL/2-1-2_5.png)
SELECT * FROM table1 LEFT JOIN table2 ON table1.key = table2.key WHERE table2.key IS NULL;RIGHT [OUTER] JOIN
![RIGHT [OUTER] JOIN](https://raw.githubusercontent.com/JabinHao/mihs/master/blog/MySQL/2-1-2_6.png)
SELECT * FROM table1 RIGHT JOIN table2 ON table1.key = table2.keyRIGHT [OUTER] JOIN without the intersection
![RIGHT [OUTER] JOIN without the intersection](https://raw.githubusercontent.com/JabinHao/mihs/master/blog/MySQL/2-1-2_7.png)
SELECT * FROM table1 RIGHT JOIN table2 ON table1.key = table2.key WHERE table2.key IS NULL;
2.1.4 实战
建表
# 建表 CREATE TABLE `tbl_emp` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `name` VARCHAR(20) DEFAULT NULL, `deptId` INT(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `fk_dept_id` (`deptId`) ) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8; CREATE TABLE `tbl_dept` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `deptName` VARCHAR(30) DEFAULT NULL, `locAdd` VARCHAR(40) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8; # 数据 INSERT INTO tbl_dept VALUES (NULL, 'RD', 1); INSERT INTO tbl_dept VALUES (NULL, 'HR', 12); INSERT INTO tbl_dept VALUES (NULL, 'MK', 13); INSERT INTO tbl_dept VALUES (NULL, 'MIS', 14); INSERT INTO tbl_dept VALUES (NULL, 'FD', 15); INSERT INTO tbl_emp VALUES (NULL, 'z3', 1); INSERT INTO tbl_emp VALUES (NULL, 'z4', 1); INSERT INTO tbl_emp VALUES (NULL, 'z5', 1); INSERT INTO tbl_emp VALUES (NULL, 'w5', 2); INSERT INTO tbl_emp VALUES (NULL, 'w6', 2); INSERT INTO tbl_emp VALUES (NULL, 's7', 3); INSERT INTO tbl_emp VALUES (NULL, 's8', 4); INSERT INTO tbl_emp VALUES (NULL, 's9', 51);七种查询
# 1.INNER JOIN SELECT * FROM tbl_dept INNER JOIN tbl_emp ON tbl_dept.id = tbl_emp.deptId; # 2. 左外连接 SELECT * FROM tbl_emp LEFT JOIN tbl_dept ON tbl_dept.id = tbl_emp.deptId; # 3. 右外连接 SELECT * FROM tbl_emp RIGHT JOIN tbl_dept ON tbl_dept.id = tbl_emp.deptId; # 4. 左外连接去交集 SELECT * FROM tbl_emp LEFT JOIN tbl_dept ON tbl_emp.deptId = tbl_dept.id WHERE tbl_dept.id IS NULL ; # 5. 右外连接去交集 SELECT * FROM tbl_emp RIGHT JOIN tbl_dept ON tbl_emp.deptId = tbl_dept.id WHERE tbl_emp.deptId IS NULL ; # 6. 全外连接 SELECT * FROM tbl_emp LEFT JOIN tbl_dept ON tbl_emp.deptId=tbl_dept.id UNION SELECT * FROM tbl_emp RIGHT JOIN tbl_dept ON tbl_emp.deptId=tbl_dept.id; # 7. 补集 SELECT * FROM tbl_emp LEFT JOIN tbl_dept ON tbl_emp.deptId=tbl_dept.id WHERE tbl_dept.id IS NULL UNION SELECT * FROM tbl_emp RIGHT JOIN tbl_dept ON tbl_emp.deptId=tbl_dept.id WHERE deptId IS NULL;
2.2 索引简介
2.2.1 索引概述
定义
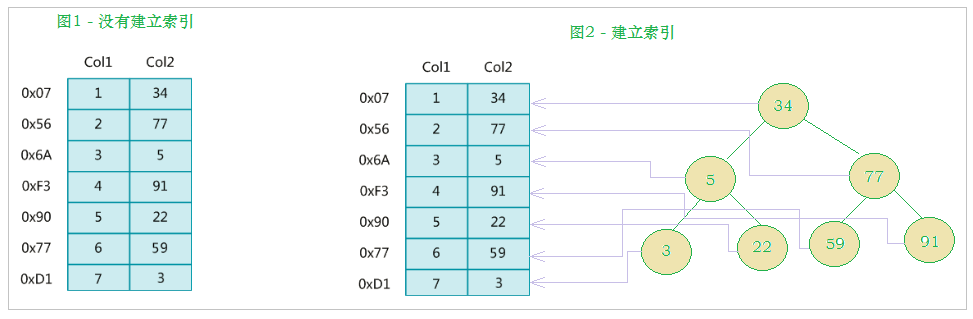
- 索引(index)是帮助MySQL高效获取数据的数据结构(有序)
- 索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。索引是数据库中用来提高性能的最常用的工具
索引示意
索引优缺点
- 类似于书籍的目录索引,提高数据检索的效率,降低数据库的IO成本。
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗
- 实际上索引也是一张表,该表中保存了主键与索引字段,并指向实体类的记录,所以索引列也是要占用空间的。
- 虽然索引大大提高了查询效率,同时却也降低更新表的速度。
2.2.2 索引结构
索引是在MySQL的存储引擎层中实现的,而不是在服务器层实现的。所以每种存储引擎的索引都不一定完全相同,也不是所有的存储引擎都支持所有的索引类型的。
MySQL目前提供了以下4种索引
- BTREE 索引 : 最常见的索引类型,大部分索引都支持 B 树索引。
- HASH 索引:只有Memory引擎支持 , 使用场景简单 。
- R-tree 索引(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少,不做特别介绍。
- Full-text (全文索引) :全文索引也是MyISAM的一个特殊索引类型,主要用于全文索引,InnoDB从Mysql5.6版本开始支持全文索引
不同存储引擎对比
索引 InnoDB MyISAM Memory BTREE 支持 支持 支持 HASH 不支持 不支持 支持 R-tree 不支持 支持 不支持 Full-text 5.6以后支持 支持 不支持 说明
- 我们平常所说的索引,如果没有特别指明,都是指B+树(多路搜索树,并不一定是二叉的)结构组织的索引。
- 聚集索引、复合索引、前缀索引、唯一索引默认都是使用 B+tree 索引,统称为索引
2.2.3 索引分类
- 单值索引 :即一个索引只包含单个列,一个表可以有多个单列索引
- 唯一索引 :索引列的值必须唯一,但允许有空值
- 复合索引 :即一个索引包含多个列
2.2.4 基本语法
创建索引
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [USING index_type] ON tbl_name(index_col_name,...)- UNIQUE:唯一索引
- index_type:默认 BTREE
查看索引
show index from table_name;删除索引
DROP INDEX index_name ON tbl_name;ALTER命令
alter table tb_name add primary key(column_list); # 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL alter table tb_name add unique index_name(column_list); # 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次) alter table tb_name add index index_name(column_list); # 添加普通索引, 索引值可以出现多次。 alter table tb_name add fulltext index_name(column_list); # 该语句指定了索引为FULLTEXT, 用于全文索引
2.2.5 索引设计原则
- 主键自动建立唯一索引
- 对查询频次较高,且数据量比较大的表建立索引
- 查询中与其他表关联的字段,外键关系建立索引
- 频繁更新的字段不适合建索引
- where条件中用不到的字段不创建索引
- 高并发下倾向于创建组合索引
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
- 查询中统计或者分组字段
2.3 性能分析
2.3.1 MySQL Query Optimizer
2.3.2 MySQL常见瓶颈
- CPU
- IO
- 服务器硬件性能瓶颈
2.3.3 优化SQL步骤
查看SQL执行频率
# 查看当前session不同语句执行次数 SHOW STATUS LIKE 'Com_______'; # 查看总的执行次数 SHOW GLOBAL STATUS LIKE 'Com_______'; # 查看Innodb SHOW STATUS LIKE 'Innodb_rows_%';定位低效率执行SQL
- 慢查询日志 : 通过慢查询日志定位那些执行效率较低的 SQL 语句
- SHOW PROCESSLIST;
explain 分析执行计划
explain SQL语句+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------+ | 1 | SIMPLE | tbl_dept | NULL | ALL | NULL | NULL | NULL | NULL | 5 | 100.00 | NULL | +----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------+show profile
- Mysql从5.0.37版本开始增加了对 show profiles 和 show profile 语句的支持。show profiles 能够在做SQL优化时帮助我们了解时间都耗费到哪里去了
- 通过 have_profiling 参数,能够看到当前MySQL是否支持profile
mysql> SELECT @@have_profiling; +------------------+ | @@have_profiling | +------------------+ | YES | +------------------+ - 默认是关闭的,可以在session中开启
set profiling=1; - 查看
# 查看所有sql语句耗时 SHOW PROFILES; # 查看具体的sql语句 SHOW PROFILE FOR QUERY query_id; # 进一步选择all、cpu、block io 、context switch、page faults等明细类型 SHOW PROFILE CPU FOR QUERY query_id;
trace分析优化器执行计划
- MySQL5.6提供了对SQL的跟踪trace, 通过trace文件能够进一步了解为什么优化器选择A计划, 而不是选择B计划
- 打开trace , 设置格式为 JSON,并设置trace最大能够使用的内存大小,避免解析过程中因为默认内存过小而不能够完整展示
SET OPTIMIZER_TRACE="enabled=on", END_MARKERS_IN_JSON=on; SET OPTIMIZER_TRACE_MAX_MEM_SIZE=100000; - 执行查询操作后,可以通过检查information_schema.optimizer_trace查看MySQL是如何执行SQL的
SELECT * FROM information_schema.OPTIMIZER_TRACE\G;
2.3.4 explain字段
建表
CREATE TABLE `t_role` ( `id` VARCHAR(32) NOT NULL, `role_name` VARCHAR(255) DEFAULT NULL, `role_code` VARCHAR(255) DEFAULT NULL, `description` VARCHAR(255) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `unique_role_name` (`role_name`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8; CREATE TABLE `t_user` ( `id` VARCHAR(32) NOT NULL, `username` VARCHAR(45) NOT NULL, `password` VARCHAR(96) NOT NULL, `name` VARCHAR(45) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `unique_user_username` (`username`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8; CREATE TABLE `user_role` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `user_id` VARCHAR(32) DEFAULT NULL, `role_id` VARCHAR(32) DEFAULT NULL, PRIMARY KEY (`id`), KEY `fk_ur_user_id` (`user_id`), KEY `fk_ur_role_id` (`role_id`), CONSTRAINT `fk_ur_role_id` FOREIGN KEY (`role_id`) REFERENCES `t_role` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION, CONSTRAINT `fk_ur_user_id` FOREIGN KEY (`user_id`) REFERENCES `t_user` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION ) ENGINE = InnoDB DEFAULT CHARSET = utf8; INSERT INTO `t_user` (`id`, `username`, `password`, `name`) VALUES ('1', 'super', '$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe', '超级管理员'); INSERT INTO `t_user` (`id`, `username`, `password`, `name`) VALUES ('2', 'admin', '$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe', '系统管理员'); INSERT INTO `t_user` (`id`, `username`, `password`, `name`) VALUES ('3', 'itcast', '$2a$10$8qmaHgUFUAmPR5pOuWhYWOr291WJYjHelUlYn07k5ELF8ZCrW0Cui','test02'); INSERT INTO `t_user` (`id`, `username`, `password`, `name`) VALUES ('4', 'stu1', '$2a$10$pLtt2KDAFpwTWLjNsmTEi.oU1yOZyIn9XkziK/y/spH5rftCpUMZa', '学生1'); INSERT INTO `t_user` (`id`, `username`, `password`, `name`) VALUES ('5', 'stu2', '$2a$10$nxPKkYSez7uz2YQYUnwhR.z57km3yqKn3Hr/p1FR6ZKgc18u.Tvqm', '学生2'); INSERT INTO `t_user` (`id`, `username`, `password`, `name`) VALUES ('6', 't1', '$2a$10$TJ4TmCdK.X4wv/tCqHW14.w70U3CC33CeVncD3SLmyMXMknstqKRe', '老师1'); INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES ('5', '学生', 'student', '学生'); INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES ('7', '老师', 'teacher', '老师'); INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES ('8', '教学管理员', 'teachmanager', '教学管理员'); INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES ('9', '管理员', 'admin', '管理员'); INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES ('10', '超级管理员', 'super', '超级管理员'); INSERT INTO user_role(id, user_id, role_id) VALUES (NULL, '1', '5'), (NULL, '1', '7'), (NULL, '2', '8'), (NULL, '3', '9'), (NULL, '4', '8'), (NULL, '5', '10');id:查询的序列号
- id 相同表示加载表的顺序是从上到下
- id 不同id值越大,优先级越高,越先被执行。
- id 有相同,也有不同,同时存在。id相同的可以认为是一组,从上往下顺序执行;在所有的组中,id的值越大,优先级越高,越先执行
select_type:表示 SELECT 的类型
select_type 含义 SIMPLE 简单的select查询,查询中不包含子查询或者UNION PRIMARY 查询中若包含任何复杂的子查询,最外层查询标记为该标识 SUBQUERY 在SELECT 或 WHERE 列表中包含了子查询 DERIVED 在FROM 列表中包含的子查询,被标记为 DERIVED(衍生) MYSQL会递归执行这些子查询,把结果放在临时表中 UNION 若第二个SELECT出现在UNION之后,则标记为UNION ; 若UNION包含在FROM子句的子查询中,外层SELECT将被标记为 : DERIVED UNION RESULT 从UNION表获取结果的SELECT table:展示这一行的数据是关于哪一张表的
type:访问类型
type 含义 NULL MySQL不访问任何表,索引,直接返回结果 system 表只有一行记录(等于系统表),这是const类型的特例,一般不会出现 const 表示通过索引一次就找到了,const 用于比较primary key 或者 unique 索引。因为只匹配一行数据,所以很快。如将主键置于where列表中,MySQL 就能将该查询转换为一个常亮。const于将 “主键” 或 “唯一” 索引的所有部分与常量值进行比较 eq_ref 类似ref,区别在于使用的是唯一索引,使用主键的关联查询,关联查询出的记录只有一条。常见于主键或唯一索引扫描 ref 非唯一性索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,返回所有匹配某个单独值的所有行(多个) range 只检索给定返回的行,使用一个索引来选择行。 where 之后出现 between , < , > , in 等操作。 index index 与 ALL的区别为 index 类型只是遍历了索引树, 通常比ALL 快, ALL 是遍历数据文件。 all 将遍历全表以找到匹配的行 key
- possible_keys : 显示可能应用在这张表的索引, 一个或多个。
- key : 实际使用的索引, 如果为NULL, 则没有使用索引。
- key_len : 表示索引中使用的字节数, 该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下, 长度越短越好
ref
- 显示了之前的表在key列记录的索引中查找值所用的列或常量
- const表示使用了常量
extra
extra 含义 using filesort 说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取, 称为“文件排序”, 效率低。 using temporary 使用了临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于 order by 和 group by; 效率低 using index 表示相应的select操作使用了覆盖索引, 避免访问表的数据行, 效率不错。
2.4 索引优化
2.4.1 索引分析
2.4.1.1 单表
建表
CREATE TABLE IF NOT EXISTS `article` ( `id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `author_id` INT(10) UNSIGNED NOT NULL, `category_id` INT(10) UNSIGNED NOT NULL, `views` INT(10) UNSIGNED NOT NULL, `comments` INT(10) UNSIGNED NOT NULL, `title` VARBINARY(255) NOT NULL, `content` TEXT NOT NULL ); INSERT INTO `article`(author_id, category_id, views, comments, title, content) VALUES (1, 1, 1, 1, '1', '1'), (2, 2, 2, 2, '2', '2'), (1, 1, 3, 3, '3', '3');查看
SHOW INDEX FROM article; EXPLAIN SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;- type 为 all
- extra出现了 Using filesort
优化1
CREATE INDEX idx_article_ccv ON article(category_id,comments,views);- type为 range
- extra 仍然有 Using filesort
- 原因:
- 先category_id,再排comments,最后排views
commits>1为范围,索引失效- comments位于中间,无法利用索引检索views,即range类型查询字段后面索引无效
优化2
DROP INDEX idx_article_ccv ON article; CREATE INDEX idx_article_cv ON article(category_id, views);- 此时type为ref
- extra中不再有Using filesort
2.4.1.2 两表
建表
CREATE TABLE IF NOT EXISTS `class` ( `id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `card` INT(10) UNSIGNED NOT NULL ); CREATE TABLE IF NOT EXISTS `book` ( `bookid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `card` INT(10) UNSIGNED NOT NULL ); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES (FLOOR(1 + (RAND() * 20)));两表查询
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;+----+-------------+-------+------+------+ | id | select_type | table | type | rows | +----+-------------+-------+------+------+ | 1 | SIMPLE | class | ALL | 20 | | 1 | SIMPLE | book | ALL | 20 | +----+-------------+-------+------+------+- type为 ALL
- rows共40条
左表加索引
ALTER TABLE class ADD INDEX idx_class_card(card);+----+-------------+-------+-------+------+ | id | select_type | table | type | rows | +----+-------------+-------+-------+------+ | 1 | SIMPLE | class | index | 20 | | 1 | SIMPLE | book | ALL | 20 | +----+-------------+-------+-------+------+左表加索引
DROP INDEX idx_class_card ON class; ALTER TABLE book ADD INDEX idx_book_card(card);+----+-------------+-------+------+------+ | id | select_type | table | type | rows | +----+-------------+-------+------+------+ | 1 | SIMPLE | class | ALL | 20 | | 1 | SIMPLE | book | ref | 1 | +----+-------------+-------+------+------+
2.4.1.3 三表
建表
CREATE TABLE IF NOT EXISTS `phone` ( `phoneid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, `card` INT(10) UNSIGNED NOT NULL ) ENGINE = INNODB; INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card)VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20))); INSERT INTO phone(card) VALUES (FLOOR(1 + (RAND() * 20)));三表查询
EXPLAIN SELECT * FROM class c LEFT JOIN book b ON c.card = b.card LEFT JOIN phone p ON b.card = p.card;+----+-------------+-------+------+------+ | id | select_type | table | type | rows | +----+-------------+-------+------+------+ | 1 | SIMPLE | c | ALL | 20 | | 1 | SIMPLE | b | ALL | 20 | | 1 | SIMPLE | p | ALL | 20 | +----+-------------+-------+------+------+建索引
ALTER TABLE book ADD INDEX idx_book_card(card); ALTER TABLE phone ADD INDEX idx_phone_card(card);+----+-------------+-------+------+------+ | id | select_type | table | type | rows | +----+-------------+-------+------+------+ | 1 | SIMPLE | c | ALL | 20 | | 1 | SIMPLE | b | ref | 1 | | 1 | SIMPLE | p | ref | 1 | +----+-------------+-------+------+------+
2.4.1.4 结论
- 尽可能减少Join语句中的NestedLoop的循环总次数:永远用小的结果集驱动大的结果集
- 优先优化NestedLoop的内层循环
- 保证Join语句中被驱动表上Join条件字段已经被索引
- 当无法保证被驱动表的Join条件字段被索引且内存资源充足的前提下,不要太吝惜JoinBuffer的设置
2.4.2 索引失效
建表
CREATE TABLE staffs ( id INT PRIMARY KEY AUTO_INCREMENT, `name` VARCHAR(24) NOT NULL DEFAULT '' COMMENT '姓名', `age` INT NOT NULL DEFAULT 0 COMMENT '年龄', `pos` VARCHAR(20) NOT NULL DEFAULT '' COMMENT '职位', `add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间' ) CHARSET utf8 COMMENT '员工记录表'; INSERT INTO staffs(NAME, age, pos, add_time) VALUES ('z3', 22, 'manager', NOW()); INSERT INTO staffs(NAME, age, pos, add_time) VALUES ('July', 23, 'dev', NOW()); INSERT INTO staffs(NAME, age, pos, add_time) VALUES ('2000', 23, 'dev', NOW());添加索引
ALTER TABLE staffs ADD INDEX idx_staffs_nameAgePos(name, age, pos);索引失效案例
全值匹配:此时有效
EXPLAIN SELECT * FROM staffs WHERE name='July'; EXPLAIN SELECT * FROM staffs WHERE name='July' AND age = 25; EXPLAIN SELECT * FROM staffs WHERE name='July' AND age = 23 AND pos='dev';+----+-------------+--------+------------+------+ | id | select_type | table | partitions | type | +----+-------------+--------+------------+------+ | 1 | SIMPLE | staffs | NULL | ref | +----+-------------+--------+------------+------+最左前法则:如果索引了多列,要遵循最左前法则,查询从索引的最左前列开始且不跳过索引中的列
EXPLAIN SELECT * FROM staffs WHERE age = 23 AND pos='dev';+----+-------------+--------+------------+------+---------+ | id | select_type | table | partitions | type | key_len | +----+-------------+--------+------------+------+---------+ | 1 | SIMPLE | staffs | NULL | ref | 74 | +----+-------------+--------+------------+------+---------+不在索引列上做任何操作(计算、函数、类型转换),会导致索引失效而转向全表扫描
EXPLAIN SELECT * FROM staffs WHERE left(name,4) ='July';+----+-------------+--------+------------+------+ | id | select_type | table | partitions | type | +----+-------------+--------+------------+------+ | 1 | SIMPLE | staffs | NULL | ALL | +----+-------------+--------+------------+------+存储引擎不能使用索引中范围条件右边的列,即 “范围之后全失效”
EXPLAIN SELECT * FROM staffs WHERE name='July' AND age > 22 AND pos='dev';+----+-------------+--------+------------+-------+ | id | select_type | table | partitions | type | +----+-------------+--------+------------+-------+ | 1 | SIMPLE | staffs | NULL | range | +----+-------------+--------+------------+-------+尽量使用覆盖索引(索引列和查询列一致),减少
select *EXPLAIN SELECT name, age, pos FROM staffs WHERE name='July' AND age = 23 AND pos='dev';+----+-------------+--------+------------+------+-------------+ | id | select_type | table | partitions | type | Extra | +----+-------------+--------+------------+------+-------------+ | 1 | SIMPLE | staffs | NULL | ref | Using index | +----+-------------+--------+------------+------+-------------+使用不等于(!=或 <>)的时候无法使用索引,会导致全表扫描
EXPLAIN SELECT * FROM staffs WHERE name!='July';+----+-------------+--------+------------+------+ | id | select_type | table | partitions | type | +----+-------------+--------+------------+------+ | 1 | SIMPLE | staffs | NULL | ALL | +----+-------------+--------+------------+------+is null,is not null也无法使用索引
EXPLAIN SELECT * FROM staffs WHERE name IS NOT NULL;+----+-------------+--------+------------+ | id | select_type | table | partitions | +----+-------------+--------+------------+ | 1 | SIMPLE | staffs | NULL | +----+-------------+--------+------------+like 以通配符开头也会导致索引失效(结尾不会)
EXPLAIN SELECT * FROM staffs WHERE name like '%July';+----+-------------+--------+------------+------+ | id | select_type | table | partitions | type | +----+-------------+--------+------------+------+ | 1 | SIMPLE | staffs | NULL | ALL | +----+-------------+--------+------------+------+- 可以通过覆盖索引解决
字符串不加单引号会导致索引失效
不加单引号:发生了自动类型转换
EXPLAIN SELECT * FROM staffs WHERE name =2000;+----+-------------+--------+------------+------+ | id | select_type | table | partitions | type | +----+-------------+--------+------------+------+ | 1 | SIMPLE | staffs | NULL | ALL | +----+-------------+--------+------------+------+加单引号
EXPLAIN SELECT * FROM staffs WHERE name = '2000';+----+-------------+--------+------------+------+ | id | select_type | table | partitions | type | +----+-------------+--------+------------+------+ | 1 | SIMPLE | staffs | NULL | ref | +----+-------------+--------+------------+------+少用or,使用or来连接时索引会失效
EXPLAIN SELECT * FROM staffs WHERE name='July' OR age = 23;+----+-------------+--------+------------+------+ | id | select_type | table | partitions | type | +----+-------------+--------+------------+------+ | 1 | SIMPLE | staffs | NULL | ALL | +----+-------------+--------+------------+------+