Kafka基本架构与概念
1. 概述
1.1 Kafka 是什么
Kafka 是一个开源的分布式事件流平台,常常被用作消息队列。
事件流
Technically speaking, event streaming is the practice of capturing data in real-time from event sources like databases, sensors, mobile devices, cloud services, and software applications in the form of streams of events;
简单来讲,事件流就是从数据库、应用等事件源中持续生产的事件数据。
1.2 Kafka 主要功能
Kafka主要提供三个功能:
- 事件流的发布和订阅
- 按照记录的生成顺序高效地存储记录流
- 实时处理记录流
Kalfka 所有功能都以分布式、高度可扩展、弹性、容错和安全的方式提供的。 Kafka 可以部署在裸机硬件、虚拟机和容器上,也可以部署在本地和云端。
1.3 Kafka 如何工作
Kafka 由客户端与服务器组成,两者之间通过 TCP 协议来通信
服务器:
- 以集群形式运行(由一个或多个服务器组成)
- Kafka集群具有很强的扩展性与容错性,一个或多个服务器故障后,会有其他服务器接管其工作
客户端
- 在分布式或微服务应用中,通过客户端操作事件流
- 支持Java、Scala,也支持Go、Python等其他语言以及 REST API
1.4 Kafka 工作模式
Kafka 提供 队列 和 发布-订阅 两种模式
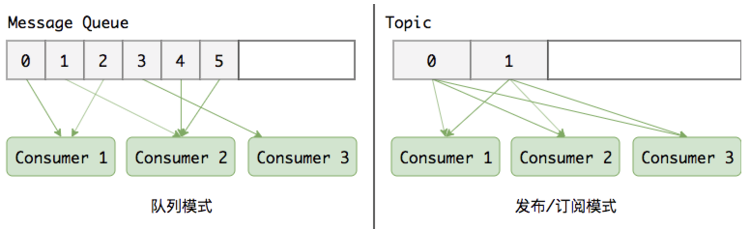
队列
- 也叫点对点
- 消息持久化到一个队列中,有一个或多个消费者消费队列中的数据,但是一条消息只能被消费一次
发布订阅
- 消息被持久化到一个topic中,消费者可以订阅一个或多个topic,消费者可以消费该topic中所有的数据
- 同一条数据可以被多个消费者消费,数据被消费后不会立马删除
2. 架构与概念
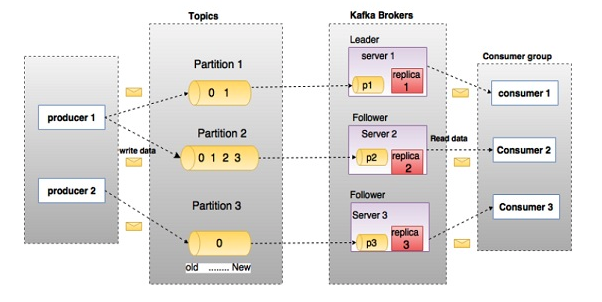
2.1 Kafka 架构
架构
2.2 概念
Producer: 生产者
- 消息生产者,即向 kafka broker 发消息的客户端
Consumer: 消费者
- 消息消费者,向kafka broker取消息的客户端
- CG:Consumer Group即消费组,广播需要每个consumer有一个独立的CG。单播则要所有的consumer在同一个CG
Topic:主题
- 发布-订阅中的topic, 消费组根据 topic 消费消息
Partition:分区
- topic中的数据分割为一个或多个partition。每个topic至少有一个partition。
- 每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,但多个partition之间无法保证顺序。
- 在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1
Broker
- 一台kafka服务器就是一个broker。
- 一个集群由多个broker组成。一个broker可以容纳多个topic
Offset
- 每条消息都有一个当前Partition下唯一的64字节的offset,它指明了这条消息的起始位置
2.3 关系
Partitions 与 Brokers
- 每个 broker 中有多个 partition
- 同一个 broker 中的每个 partition 都可以作为某个 topic 的主分区或备份分区
Leader 与 replica
- 每个 topic 由一个主分区和若干备份分区组成
- 主分区负责读写,备份分区只负责备份
Consumer 与 Consumer Group(CG)
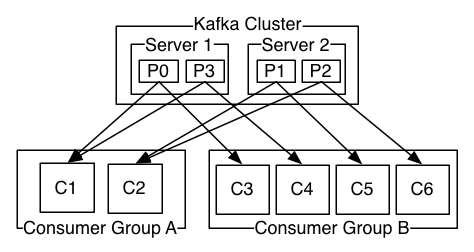
- 消费组作为一个整体按照 发布-订阅消息模型 来消费消息
- 同一个消费组的内部,消费者按照消息队列模型来消费消息
3. 其它
3.1 Kafka 与 RabbitMQ
两者对比
Kafka RabbitMQ 语言 Scala erlang 吞吐量 非常高 高 可用性 非常高(分布式) 高(主从) 持久化 支持大量堆积 支持少量堆积 协议 TCP 高级消息收发队列协议 (AMQP) 及通过插件获得的支持:MQTT、STOMP …
3.2 分区算法
- 将所有 broker (n个) 和 待分配 partition 排序
- 将第 i 个 partition 分配到第 (
i % n) 个broker上 - 将第 i 个 partition 的第 j 个 replica 分配到第
(i + j) % n个 broker 上
3.3 数据检索机制
Kafka 文件结构
- partition 在实际的存储结构中是一个目录,命名规则为 topic + partition序号
- segment 由两个文件组成,索引文件 *.index 和 消息内容文件 *.log
消息存储
- 消息按顺序产生,每个消息都有一个序号 offset,从0开始
- segment文件以上一个segment最后一个offset命名,文件名长度固定20位(不足补零,如00000000000000000300.index)
- index文件存储键值对:key为offset,value为 .log中的偏移量
数据检索
- 二分查找,先根据 offset 找到对应的 segment
- 从 index 中找到其物理偏移量
- 到 log 文件中读取消息内容
3.4 数据安全性
ack应答机制
- 可以通过 acks 参数指定Producer 向 Broker 发送数据时的消息确认机制(request.required.acks)
- acks = 0:无需等待确认而继续发送
- acks = 1:Producer在ISR中的Leader已成功收到的数据并得到确认后发送下一条message。如果Leader宕机了,则会丢失数据
- acks = -1(all):producer需要等待ISR中的所有Follower都确认接收到数据后才算一次发送完成,可靠性最高
ISR 机制
相关概念
- ISR(In-Sync Replicas ):与leader保持同步的follower集合
- OSR(Outof-Sync Replicas):离开同步队列的副本
- AR(Assigned Replicas):分区的所有副本,=ISR + OSR
机制
- Leader维护一个动态的in-sync replica set (ISR-同步副本列表),意为和leader保持同步的follower集合。
- ISR中的follower完成数据的同步之后,leader就会给follower发送ack。如果follower长时间未向leader同步数据,则该follower将被踢出ISR
- 副本的滞后于 leader 是根据 replica.lag.max.messages 或 replica.lag.time.max.ms 来衡量的; 前者用于检测慢副本(Slow replica),而后者用于检测卡住副本(Stuck replica)