Chapter8 RabbitMQ 集群
8.1 搭建
8.1.1 搭建集群
修改主机名
vim /etc/hostname reboot # 重启修改主机名会导致RabbitMQ丢失之前的数据,包括创建的用户
配置各个节点的 hosts 文件,让各个节点都能互相识别对方
# /etc/hosts node1的IP node1 node2的IP node2 node3的IP node3如果用的是服务器,有一行是私有IP跟主机名,需要注释掉
确保各个节点的 cookie 文件使用的是同一个值
# 在 node1 上执行远程操作命令 scp /var/lib/rabbitmq/.erlang.cookie root@node2:/var/lib/rabbitmq/.erlang.cookie scp /var/lib/rabbitmq/.erlang.cookie root@node3:/var/lib/rabbitmq/.erlang.cookie启动 RabbitMQ 服务,顺带启动 Erlang 虚拟机和 RbbitMQ 应用服务(在三台节点上分别执行以下命令)
rabbitmq-server -detached将节点2加入集群
# 在 node2 上操作 rabbitmqctl stop_app rabbitmqctl reset rabbitmqctl join_cluster rabbit@node1 rabbitmqctl start_app将节点3加入集群
# 在 node3 上操作 rabbitmqctl stop_app rabbitmqctl reset rabbitmqctl join_cluster rabbit@node1 # 这里node2也是可以的,因为node1跟node2已经是一个集群了 rabbitmqctl start_app集群状态
rabbitmqctl cluster_status
8.1.2 移除节点
将要移除的节点停机
/sbin/service rabbitmq-server stop主机上查看要移除的节点是否停机
rabbitmqctl cluster_status在主机上移除要移除的节点
rabbitmqctl forget_cluster_node rabbit@node3--offline选项,用于删除最后一个节点
8.2 镜像队列
8.2.1 说明
- 如果 RabbitMQ 集群中只有一个 Broker 节点,那么该节点的失效将导致整体服务的临时性不可用,并且也可能会导致消息的丢失
- 即使设置消息、队列持久化也无法避免由于缓存导致的问题:因为消息在发送之后和被写入磁盘并执行刷盘动作之间存在一个短暂却会产生问题的时间窗
- 通过 publisherconfirm 机制能够确保客户端知道哪些消息己经存入磁盘,尽管如此, 一般不希望遇到因单点故障导致的服务不可用。
- 引入镜像队列(Mirror Queue)的机制,可以将队列镜像到集群中的其他 Broker 节点之上,如果集群中的一个节点失效了,队列能自动地切换到镜像中的另一个节点上以保证服务的可用性
8.2.2 搭建
步骤
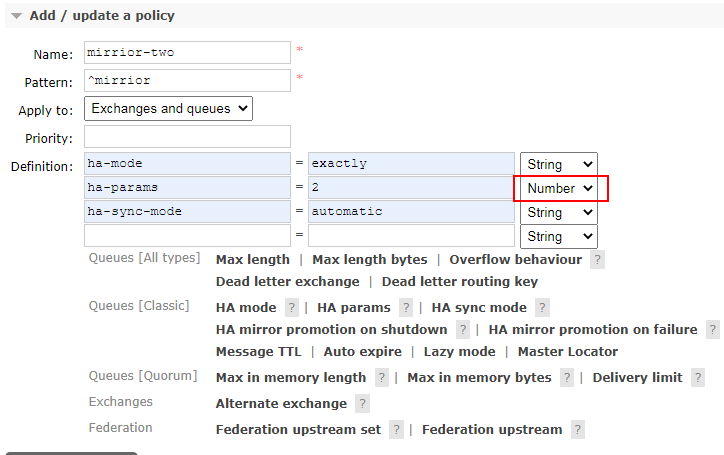
说明
- Name:策略名,可以随意起
- Pattern:正则表达式,这里表示为 mirrior开头的队列创建镜像队列
- ha-mode:镜像队列模式,
- all:在集群所有节点上进行镜像
- exactly:在指定个数的节点上镜像,节点个数由 ha-params 指定
- nodes:在指定节点上进行镜像,节点名称通过ha-params 指定
- ha-params:exactly 模式下为数字表述镜像节点数,nodes 模式下为节点列表表示需要镜像的节点
- ha-sync-mode:镜像队列中消息的同步方式,其值可为”automatic”或”manually”.
8.3 Haproxy+Keepalive 实现高可用负载均衡
8.3.1 说明
架构
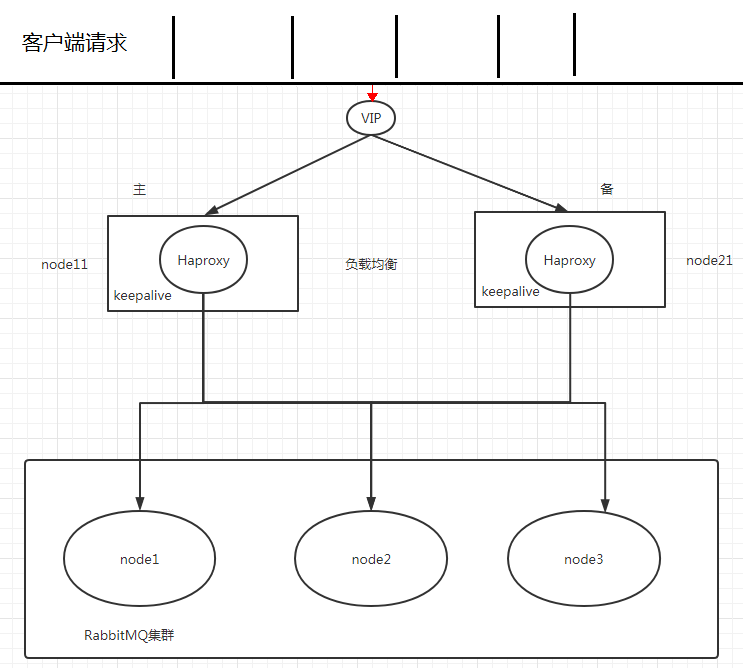
Haproxy 实现负载均衡
- HAProxy 提供高可用性、负载均衡及基于 TCP HTTP 应用的代理,支持虚拟主机
- HAProxy 实现了一种事件驱动、单一进程模型,此模型支持非常大的井发连接数
- 同类软件:nginx, lvs
8.3.2 Haproxy 负载均衡
安装(node1 和 node2)
yum -y install haproxy配置
# 修改配置文件(node1 和 node2 相同) vim /etc/haproxy/haproxy.cfg修改为以下内容:
# 前面的不动 defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000 #--------------------------------------------------------------------- ### haproxy 监控页面地址是:http://IP:9188/hastatus listen admin_stats bind *:9188 #监听的地址和端口,默认端口1080 mode http #模式 option tcplog stats refresh 5s #页面自动刷新间隔,每隔5s刷新 stats uri /hastatus #访问路径,在域名后面添加/stats可以查看haproxy监控状态,默认为/haproxy?stats stats realm welcome login\ Haproxy #提示信息,空格之前加\ stats auth admin:hjp356908 #登陆用户名和密码 stats hide-version #隐藏软件版本号 stats admin if TRUE #当通过认证才可管理 #------------------------------------------------- frontend rabbitmq mode tcp bind *:5679 timeout client 168h default_backend rabbitmq_nodes log global option tcplog option logasap backend rabbitmq_nodes mode tcp balance roundrobin server node1 139.224.113.9:5672 check inter 5000 rise 2 fall 3 weight 1 server node2 139.224.221.186:5672 check inter 5000 rise 2 fall 3 weight 1 server node3 47.103.72.213:5672 check inter 5000 rise 2 fall 3 weight 1 #rabbitmq 集群配置 listen rabbitmq_admin bind 0.0.0.0:15679 mode http balance roundrobin server node1 139.224.113.9:5672 check inter 5000 rise 2 fall 3 weight 1 server node2 139.224.221.186:5672 check inter 5000 rise 2 fall 3 weight 1 server node3 47.103.72.213:5672 check inter 5000 rise 2 fall 3 weight 1启动
haproxy -f /etc/haproxy/haproxy.cfg ps -ef | grep haproxy查看
8.4 Federation Exchange 与 Federation Queue
8.4.1 说明
- 联邦机制的实现,依赖于RabbitMQ的Federation插件,该插件的主要目标是为了RabbitMQ可以在多个 Broker节点或者集群中进行消息的无缝传递
- Federation插件可以让多个交换器和多个队列进行联邦。一个联邦交换器或者一个联邦队列接受上游(位于其他Broker上的交换器和队列)消息。
- 联邦交换器能够将原本发送给上游交换器(upstream exchange)的消息路由到本地的某个队列中
- 联邦队列则允许一个本地消费者接收到来自上游队列(upstream queue)的消息
8.4.2 联邦交换机搭建
原理
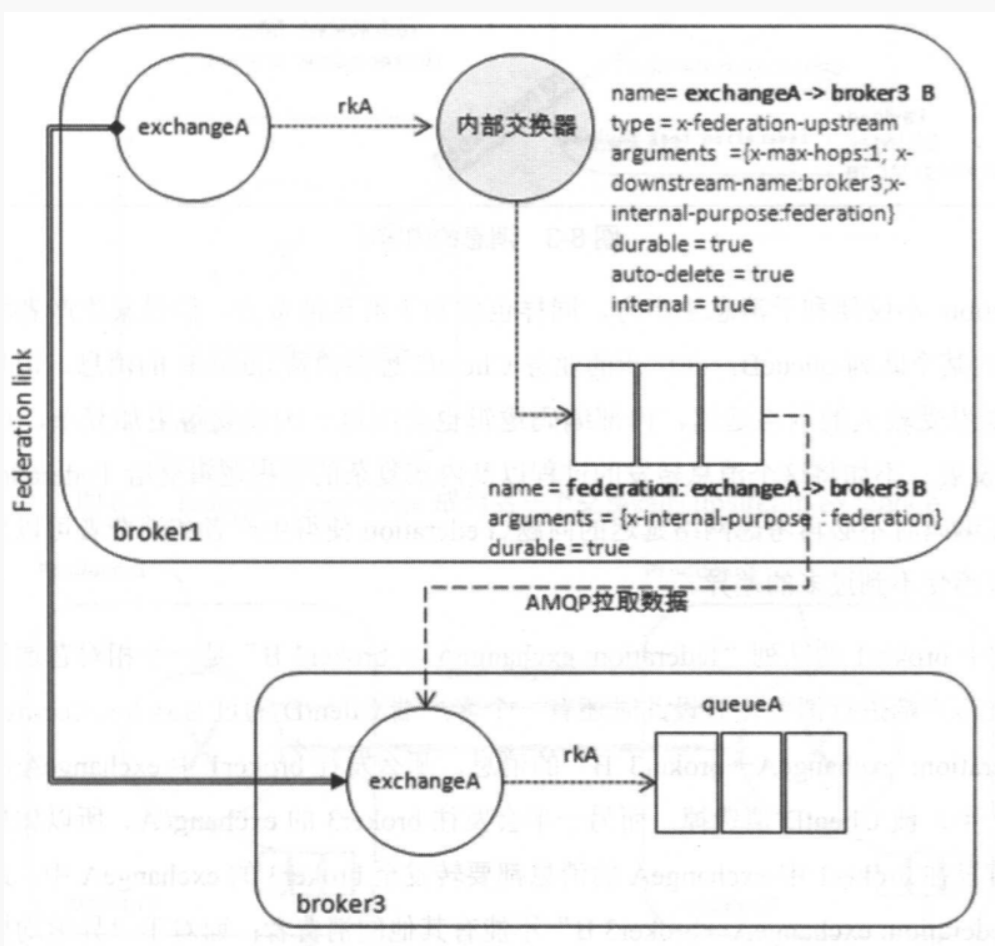
- 有两个集群node1(上图的broker1)和node2(broker3),距离较远
- node1附近的Client要向node2上传消息,会有很高的延迟
- 联邦后,broker1 的交换机直接接收消息,返回确认,消息再经Federation link转发给 broker3
在每台机器上开启 federation 相关插件
rabbitmq-plugins enable rabbitmq_federation rabbitmq-plugins enable rabbitmq_federation_management首先要运行 consumer 在 node2 创建 fed_exchange(即上图的exchangeA)
ConnectionFactory factory = new ConnectionFactory(); factory.setHost("node2的IP"); factory.setUsername("admin"); factory.setPassword("password"); final Connection connection = factory.newConnection(); final Channel channel1 = connection.createChannel(); channel.exchangeDeclare(FED_EXCHANGE, BuiltinExchangeType.DIRECT); channel.queueDeclare("node2.queue", true, false, false, null); channel.queueBind("node2.queue", FED_EXCHANGE, "routing.key"); DeliverCallback deliverCallback = (consumerTag, message) -> { System.out.println(new String(message.getBody())); }; channel1.basicConsume("node2.queue", true, deliverCallback, consumerTag -> { System.out.println("消费消息被中断"); } );在 downstream(node2)配置 upstream(node1)
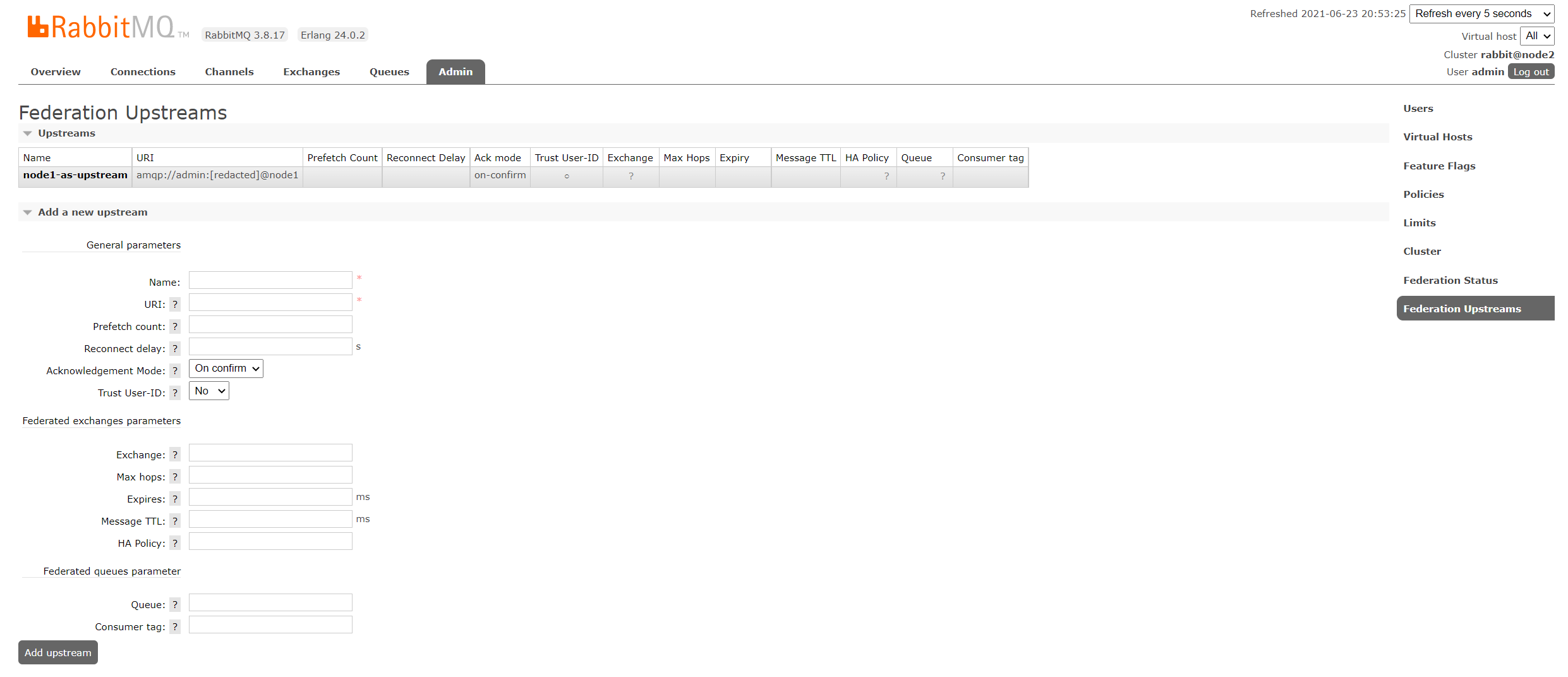
- Name:随意起,等会会用到
- URI:amqp://用户名:密码@node1
定义policy(node2)
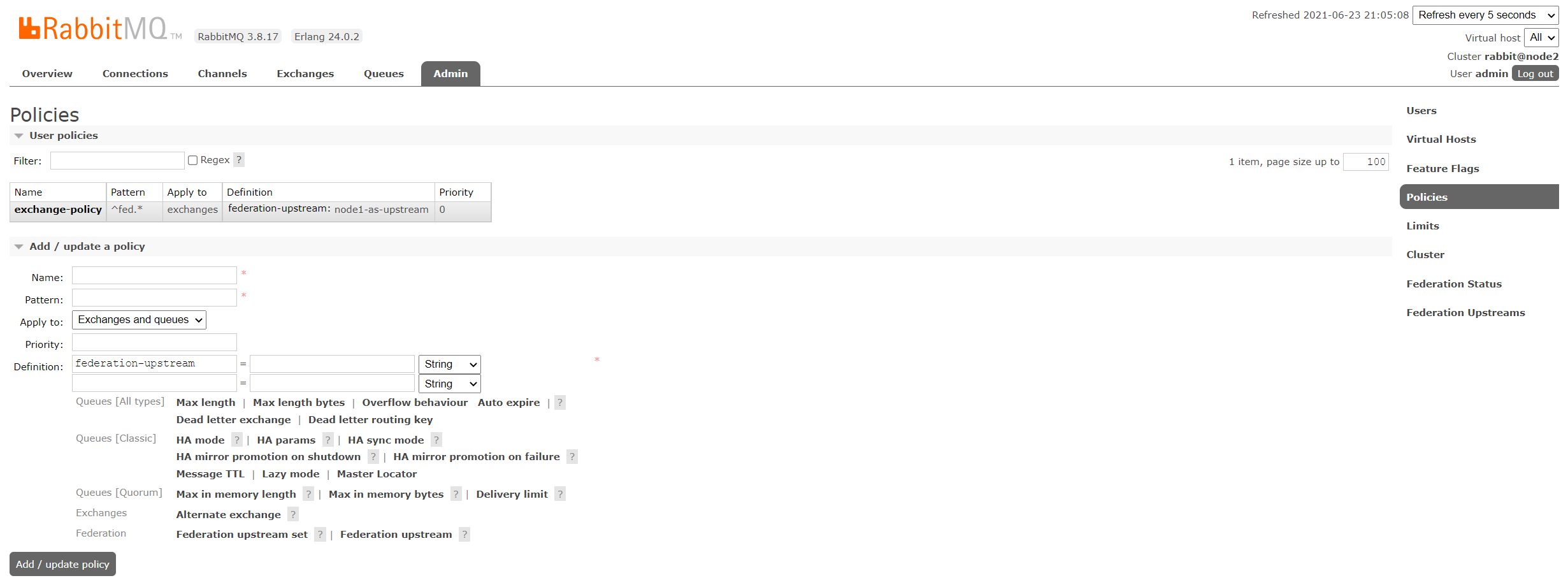
- Name:随意
- Pattern:正则表达式,^fed.*
- Apply to:Exchanges
- Definition:federation-upstream = upstream名
8.4.3 Federation Queue 搭建
原理
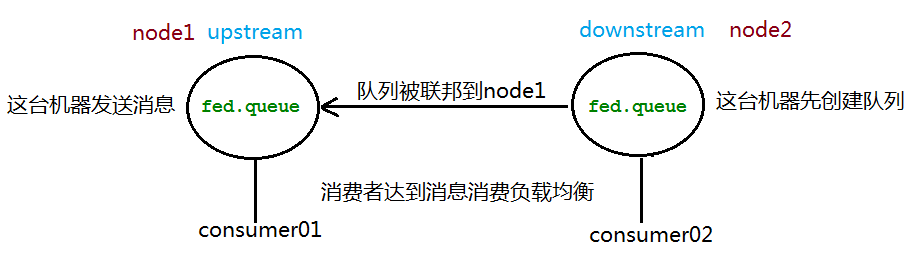
- 以 node1 为上游队列,node2 被联邦到 node1
- node2 可以接收到来自 node1 的消息
- 也可以互为联邦队列,一条消息可以在联邦队列间转发无限次
- federation queue只能使用Basic.Consume进行消费,并且不具备传递性
添加 upstream (同上)
添加Ploicy
- 将 Apply to改为 Queues
- 其它同上
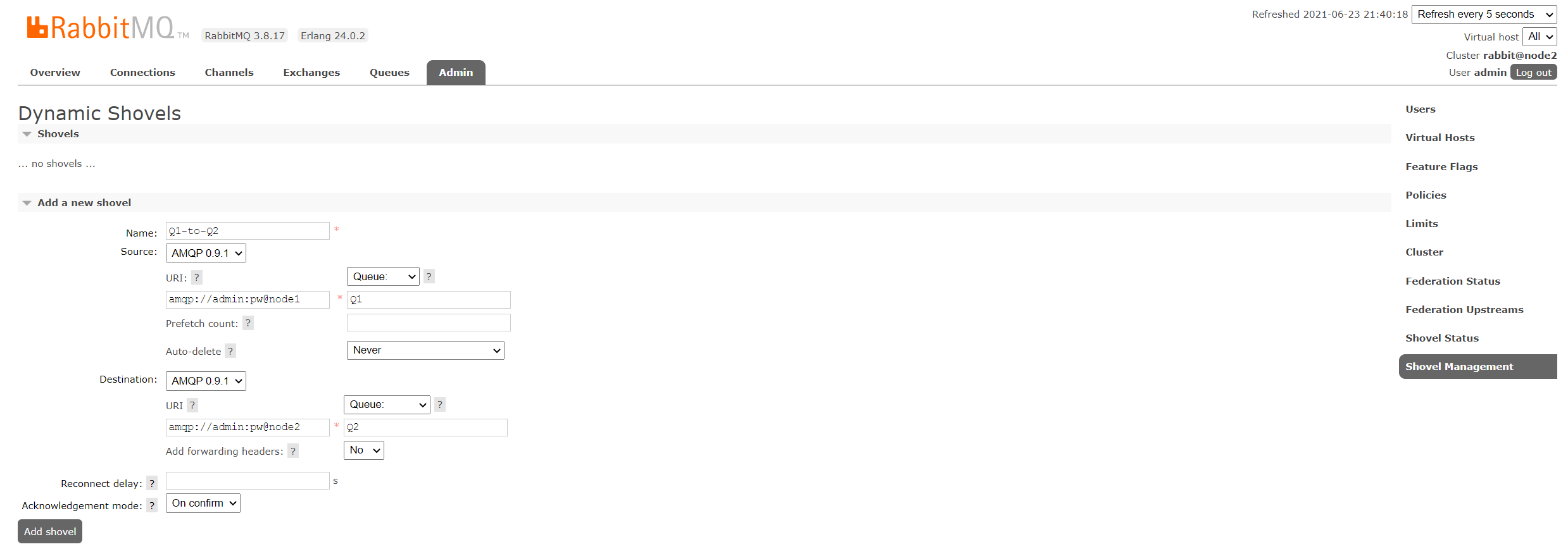
8.6 Shovel
8.6.1 说明
与 Federation 具备的数据转发功能类似, Shovel 能够可靠、持续地从一个 Broker 中的队列拉取数据并转发至另一个 Broker 中的交换器
作为源端的队列和作为目的端的交换器可以同时位于同一个 Broker ,也可以位于不同的 Broker 上
原理
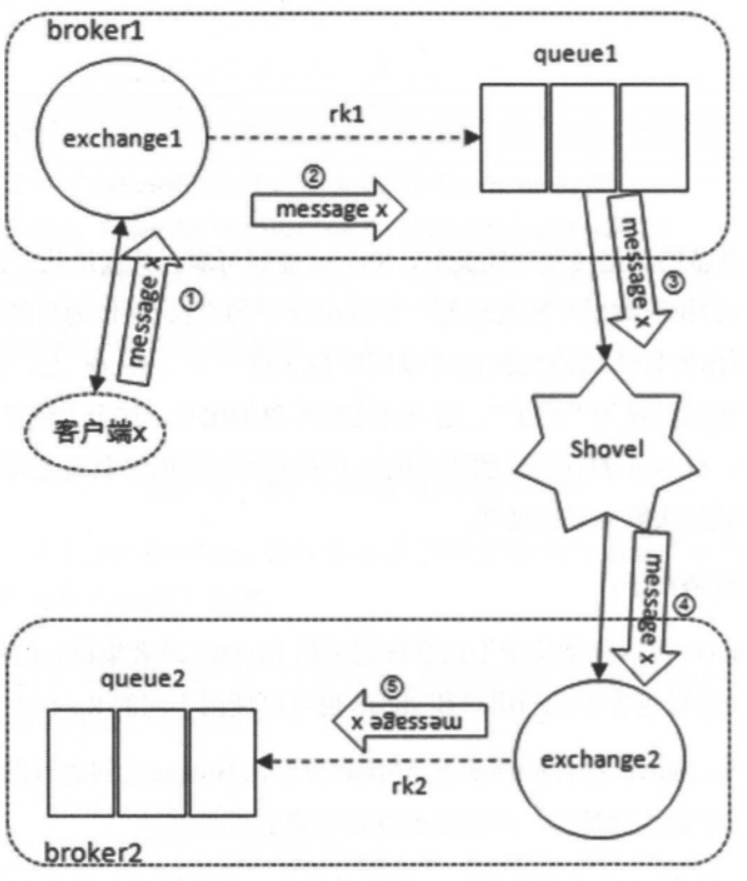
- 在队列 queue1 和交换器 exchange2 之间配置一个 Shovel link,当一条内容为 shovel test payload 的消息从客户端发送至交换器 exchange1 的时候,这条消息会经过上图中的数据流转最后存储在队列 queue2 中
- 通常情况下,使用 Shovel 时配置队列作为源端,交换器作为目的端,但同样可以将队列配置为目的端:(通过broker2的默认交换器转发)
8.6.2 搭建
启动插件
rabbitmq-plugins enable rabbitmq_shovel rabbitmq-plugins enable rabbitmq_shovel_management添加 shovel 源和目的地